火山引擎veStack智算版,构建智能时代高性能AI云底座
AI大模型技术的发展和应用,给各行各业智能化升级带来了巨大的机遇和挑战,尤其是对算力提出了极高的要求。为了帮助行业客户更好应对算力的迫切需求,火山引擎veStack混合云全新推出智算版,通过构建高性能的异构算力底座,提供AI大模型训练到推理的全流程能力。
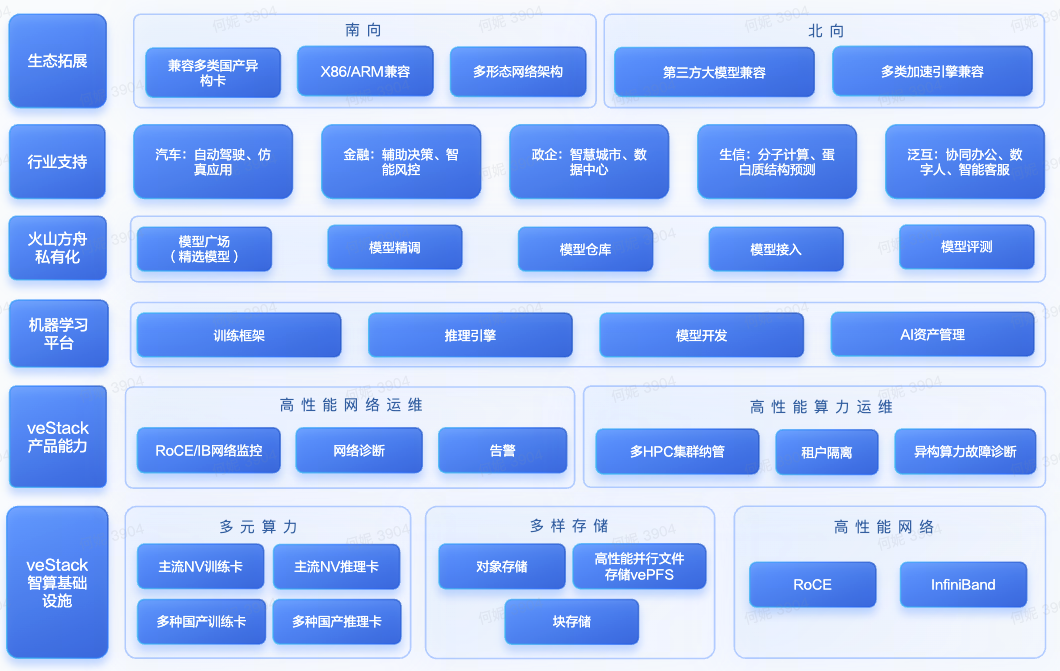
火山引擎veStack 智算版是专为智算场景打造的AI云底座,具有开放兼容、高性能大规模、全栈AI能力等产品优势,满足企业使用大模型服务、算力租赁服务以及打造专属大模型等需求,为各行各业的智能化升级提供了一个合规、普惠的AI原生基础设施。
开放兼容:兼容十余种训练、推理卡
AI大模型的训练和推理,需要依赖于强大的算力支撑。然而,目前市场上的算力产品,往往存在着不同的架构、接口、驱动、软件等,导致算力的兼容性和互操作性较低,给用户带来了使用和管理的困难。例如,用户可能需要针对不同的算力产品,进行不同的环境配置、代码适配、性能调优等,增加了用户的成本和风险。
为了解决这一问题,火山引擎veStack 智算版提供了一个开放兼容的智算基础设施,支持兼容十余种训练、推理卡,包括NVIDIA以及各类国产主流厂商的GPU、NPU、IPU等产品。用户可以在veStack智算版上,无缝地使用不同算力产品,无需进行额外的配置和适配,即可实现算力的快速接入和部署。同时,veStack智算版还会持续对算力进行兼容适配、升级迭代,打造一个高性能的异构算力底座,满足用户的不同算力需求和场景。
高性能大规模:支持3.2Tbps RDMA带宽,单集群可支持万卡以上规模
AI大模型的训练和推理,不仅需要强大的单卡算力,还需要高效的多卡协同和扩展能力。然而,目前市场上的算力产品,往往存在着网络带宽、存储性能、集群规模等方面的瓶颈,导致算力的性能和效率受到限制,给用户造成性能和成本的损失。
为此,火山引擎veStack 智算版提供了一个高性能大规模的智算基础设施,支持3.2Tbps RDMA带宽,单集群可支持万卡以上规模。用户可以在veStack 智算版上,利用高性能无损网络和高性能并行文件存储,实现多卡之间的高效协同和扩展,提升训练和推理的性能和效率。
全栈AI能力:一站式建设专属大模型
随着大模型技术的发展,业界发现通用基础大模型难以满足各行业细分场景下的特定需求,同时基于数据安全、合规性等行业监管要求,政府、金融等行业客户更倾向于在本地数据中心部署专属的行业大模型。
在这一背景下,火山引擎veStack 智算版提供了一个全栈AI能力的智算基础设施,可支持企业客户部署火山方舟,并提供丰富的精选大模型。如金融行业用户就可以在veStack 智算版上,享受从底层算力基础设施、机器学习平台、火山方舟一站式大模型服务平台以及各种专业服务的全流程AI能力支持,实现AI应用的快速开发和部署。
为了给企业提供灵活、高效的算力资源,veStack 智算版还提供了多种算力服务模式,包括云服务、软硬一体买断以及纯软买断和订阅等,用户可以根据自身业务需求,灵活选择火山引擎提供的GPU专区或者自建IDC等方案,满足其算力以及业务合规等诉求。
当前,veStack 智算版在各行各业均有丰富的行业落地实践,已助力汽车、金融、生信等多行业客户建设开放兼容、高性能、具备全栈AI能力的智算中心,帮助客户实现云上创新,持续增长。未来,火山引擎将继续深耕智算领域,为用户提供更优质的智算服务和解决方案,共同推动各行业的智能化升级。